【发布时间:2026年4月10日】
2026年2月11日,科大讯飞正式发布基于全国产算力训练的讯飞星火X2大模型,标志着国产AI助手技术进入全新阶段-。作为当前国内大模型领域的标杆产品,AI助手讯飞凭借293B参数的MoE稀疏架构和深度推理能力,在数学、推理、逻辑、语言理解及智能体交互等核心能力上全面对标国际顶尖水平-。无论是技术入门者、在校学生,还是备考面试的开发者,理解大模型背后的技术原理与应用逻辑,已成为AI时代的必修课。本文将围绕“从概念到落地”的主线,由浅入深地带你读懂讯飞星火大模型——涵盖核心架构、代码调用、底层原理和高频面试题,帮你建立完整的技术认知链路。

一、为什么需要大模型?传统AI的痛点分析
在讯飞星火这类大模型出现之前,传统的AI任务处理方式存在明显的局限性。以智能对话系统为例,传统方案通常采用“意图识别+槽位填充+规则匹配”的组合模式,需要为每个业务场景单独训练模型。
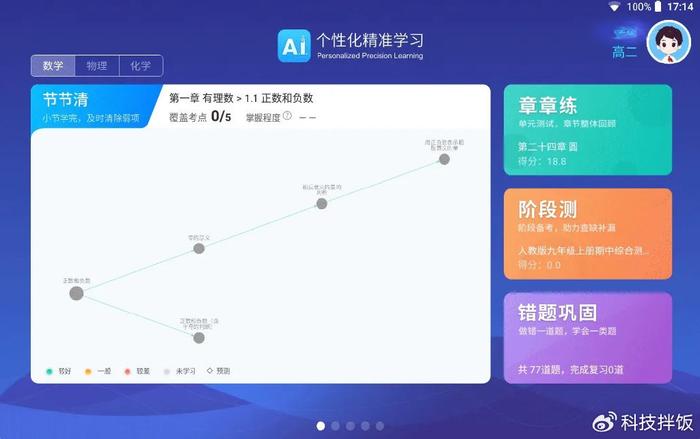
传统实现伪代码示意:
传统规则匹配式对话 def traditional_chat(user_input): 意图识别(需预先训练分类器) intent = intent_classifier.predict(user_input) 槽位提取(需维护实体词典) slots = slot_extractor.extract(user_input) 规则匹配(if-else爆炸) if intent == "query_weather": city = slots.get("city", "北京") return weather_api.query(city) elif intent == "book_ticket": 另一套逻辑... pass 无法处理未预定义的意图 return "抱歉,我还没学会这个功能"
传统方案的主要痛点:
扩展性差:每新增一个意图就需要重新训练模型或增加if-else分支,代码随业务膨胀失控;
维护成本高:意图分类器、槽位提取器、规则引擎各自独立,跨团队协作困难;
泛化能力弱:遇到未在训练集中出现的表达方式(如“明儿天咋样”查询天气),系统极易误判;
对话连续性差:传统模型缺乏上下文记忆能力,多轮对话需要额外引入状态管理模块。
讯飞星火大模型的设计初衷,正是要打破上述困境——用一个统一的、具备通用理解能力的基座模型,替代碎片化的专项模型,实现从“单一任务响应”到“通用智能对话”的范式跃迁。
二、核心概念讲解:MoE混合专家架构
标准定义
MoE(Mixture of Experts,混合专家模型) 是一种稀疏激活的大模型架构设计思想。其核心理念是:让模型内部包含多个“专家子网络”,每个输入只激活其中最适配的若干专家进行计算,而非激活全部参数。
关键词拆解
专家(Expert) :模型内部的独立前馈网络子模块,每个专家擅长处理特定类型的任务(如数学推理、代码生成);
路由器(Router/Gate Network) :一个轻量级的决策网络,负责判断当前输入应该分配给哪些专家;
稀疏激活(Sparse Activation) :对于任何一个输入,只调用全体专家中的一小部分,大幅降低计算成本。
生活化类比
想象一家大型医院:
全科医生(路由器) :患者进门,先由全科医生快速判断症状,决定应该挂哪个科室的号;
专科医生(专家) :心内科医生专治心脏问题,骨科医生擅长骨骼疾病,各有专攻;
稀疏激活 :挂号的永远是少数几个科室,而非让所有科室医生同时为一位患者服务。
同理,MoE架构下的大模型,总参数量虽大,但每个输入只激活少数专家,推理效率大幅提升。
讯飞星火X2的MoE技术参数
讯飞星火X2采用293B总参数量的MoE稀疏架构,激活参数约30B,结合权重量化、低精度KVCache、分层通信等工程优化,单台国产服务器即可高效部署,推理性能较前代X1.5提升约50%-。
三、关联概念讲解:Transformer vs MoE
Transformer标准定义
Transformer是一种基于自注意力机制(Self-Attention) 的序列建模架构,由Vaswani等人在2017年提出。它通过计算输入序列中每个元素与其他元素之间的注意力权重,实现对长距离依赖关系的捕捉,是大模型的基石性架构。
二者的关系总结
| 维度 | Transformer | MoE |
|---|---|---|
| 定位 | 基础架构层 | 架构优化层 |
| 作用 | 提供注意力机制与序列建模能力 | 在Transformer基础上实现参数稀疏化 |
| 关系 | MoE是构建在Transformer框架之上的改进方案 | Transformer中FFN层可被MoE层替代 |
一句话记忆:Transformer是“如何计算注意力”的基础设计,MoE是“如何让模型变大但计算量可控”的工程方案——Transformer搭台,MoE唱戏。
简单示例说明运行机制
输入:"解释什么是牛顿第一定律" → Transformer自注意力层:捕捉"解释""牛顿""定律"之间的语义关联 → MoE路由器:判断该输入属于"物理知识"域,激活物理专家模块 → 被激活的专家:专注于物理概念的推理和解释 → 输出:牛顿第一定律的定义与示例
四、概念关系与区别总结
清晰梳理MoE与Transformer的逻辑关系:
| 维度 | MoE(混合专家架构) | Transformer(变换器架构) |
|---|---|---|
| 思想层面 | 分治思想:不同专家处理不同任务 | 统一注意力:全局上下文建模 |
| 实现层面 | 稀疏激活路由机制 | 注意力计算矩阵运算 |
| 解决的问题 | 模型规模扩展时的计算效率问题 | 长序列依赖关系建模问题 |
| 讯飞星火X2中的体现 | 293B参数仅激活30B | 作为底层架构支撑注意力计算 |
一句话高度概括:Transformer提供了大模型的“骨架”与“注意力灵魂”,MoE则为模型装上了“按需调用的专家大脑”,二者协同实现“大而不笨”的智能效果。
五、代码示例:调用讯飞星火大模型API
1. 准备工作
在讯飞开放平台注册账号并创建应用,获取APPID、APISecret、APIKey三个凭证-。
2. 极简调用示例(Python)
spark-ai-python 极简调用示例 import sparkai 初始化客户端(填入申请的凭证) client = sparkai.Client( app_id="your_app_id", api_key="your_api_key", api_secret="your_api_secret" ) 发起对话请求 response = client.chat( messages=[ {"role": "system", "content": "你是一名AI编程助手,擅长解释技术概念"}, {"role": "user", "content": "请用一句话解释什么是MoE架构"} ], model="spark-x2" 指定星火X2模型 ) print(response.choices[0].message.content) 输出示例:MoE架构是一种让大模型拥有多个专家子网络、每次只激活少数专家进行计算的稀疏激活设计。
3. 多轮对话与上下文记忆
维护会话历史,实现多轮对话 conversation_history = [] def chat_with_context(user_input): 将用户输入追加到历史 conversation_history.append({"role": "user", "content": user_input}) response = client.chat( messages=conversation_history, model="spark-x2" ) assistant_reply = response.choices[0].message.content conversation_history.append({"role": "assistant", "content": assistant_reply}) return assistant_reply 示例:连续对话 print(chat_with_context("我是小明")) 模型记录身份 print(chat_with_context("我叫什么名字?")) 模型回答"你叫小明"
4. 新旧对比:传统方案 vs 讯飞星火方案
| 对比维度 | 传统意图识别+规则引擎 | 讯飞星火大模型 |
|---|---|---|
| 代码量 | 数百行规则与分类器 | 10行以内核心调用 |
| 新场景扩展 | 需重新训练模型+编写规则 | 仅需调整Prompt提示词 |
| 未预定义输入 | 大概率失败或返回默认兜底 | 具备泛化理解能力 |
| 多轮对话 | 需额外维护状态机 | API原生支持上下文拼接 |
| 维护成本 | 高(多模块协同) | 低(统一API接口) |
执行流程说明:用户输入 → HTTP请求携带历史会话 → 讯飞服务端经Transformer注意力计算 + MoE路由分配专家 → 生成响应 → 返回结果并更新会话历史。
六、底层原理与技术支撑
讯飞星火大模型的核心底层技术支撑如下:
| 技术组件 | 作用说明 | 在讯飞星火中的体现 |
|---|---|---|
| 自注意力机制 | 计算输入序列中元素间的关联权重 | 支撑长文本理解与复杂语义解析 |
| MoE路由算法 | 决定每个输入分配给哪些专家 | 293B总参数,仅激活约30B,稀疏高效 |
| 权重量化 | 将32位浮点参数压缩为低位表示 | 降低显存占用,支持单国产服务器部署 |
| KVCache | 缓存已计算的注意力键值对 | 避免重复计算,加速推理过程 |
| 分布式训练框架 | 多卡多机并行训练 | 攻克国产算力MoE训练效率难题- |
深度推理机制:讯飞星火X2通过训推采样校准强化学习、递归高难数据合成及多阶段高吞吐采样算法,在数学推理和复杂任务处理上的表现显著提升-。这背后依赖于强化学习(RLHF) 技术,通过人类反馈持续优化模型行为。
七、高频面试题与参考答案
面试题1:请解释MoE架构的原理及其优势?
标准答案要点:
定义:MoE(Mixture of Experts,混合专家模型)是一种稀疏激活架构,包含多个专家子网络和一个路由器网络。
核心机制:路由器对每个输入计算分配到各专家的概率,只激活Top-K个专家进行计算。
优势:
总参数量大,模型容量高;
每次推理仅激活部分参数,计算成本可控;
不同专家可专注不同任务域,提升专业化能力。
讯飞星火案例:星火X2采用293B MoE架构,激活参数仅30B,推理性能提升50%。
面试题2:大模型是如何实现“上下文记忆”的?与传统对话系统有何不同?
标准答案要点:
实现机制:大模型采用Transformer自注意力机制,能够在一个输入序列中同时看到所有历史信息。多轮对话时,将历史会话拼接在用户输入之前,模型基于注意力权重自动捕捉关键上下文。
与传统系统对比:
传统:需外部状态管理(Redis/数据库),独立维护会话状态;
大模型:输入-输出范式统一,无需额外状态模块。
局限性:受限于上下文窗口长度(讯飞星火支持数十K级别),超长对话需摘要压缩。
面试题3:讯飞星火X2相比前代有哪些核心技术升级?
标准答案要点:
算力底座:基于全国产算力训练,实现国产技术自主可控-。
架构优化:采用293B MoE稀疏架构,结合权重量化、低精度KVCache、分层通信等工程创新,推理性能提升约50%-。
深度推理增强:训推采样校准强化学习+递归高难数据合成,数学、推理、逻辑能力全面提升。
多语言能力:130+语种覆盖,拉美、东盟等地区语种保持业界领先-。
智能体能力:在智能体交互和工具调用方面对标国际最优水平。
面试题4:大模型的“幻觉”问题是如何产生的?如何缓解?
参考答案要点:
产生原因:模型本质是概率生成器,训练数据中的偏差、知识截止后的时效性问题、解码策略的随机性都可能导致“幻觉”。
缓解策略:
RAG(检索增强生成):外挂知识库辅助事实核查;
Prompt约束:在系统指令中明确要求“不确定时回答不知道”;
温度参数调低:减少生成的随机性;
多轮澄清:通过追问引导模型自我修正。
八、结尾总结
回顾全文,我们从传统AI的痛点出发,逐步深入讯飞星火大模型的核心技术体系:
核心概念:理解了MoE混合专家架构的设计思想——用一个路由器按需激活专家,实现“大而不笨”;
关联概念:理清了Transformer与MoE的关系——前者是骨架,后者是增强方案;
代码实践:掌握了调用讯飞星火API的方法,从单轮到多轮对话,对比新旧方案的显著差异;
底层原理:了解了权重量化、KVCache等工程优化如何支撑高效部署;
面试准备:梳理了高频考点,包括MoE原理、上下文记忆机制、版本升级要点、幻觉问题处理。
易错点提醒:面试中常被问“MoE是否替代了Transformer”,务必明确——MoE是在Transformer框架内对FFN层的改造,二者是增强关系而非替代关系。
下一篇预告:我们将深入RAG(检索增强生成)技术,讲解如何为讯飞星火接入私有知识库,让大模型准确回答企业专属问题,敬请期待!